Verifying someone’s identification on the web can be tough, but there are a few services that we trust to be the true source of someone’s online presence. How can we use these services to verify someone’s identity to prevent them from having to create yet another online account? That’s where OAuth comes in.
You may or may not have heard of OAuth but I’m sure you’ve seen log in options that look something like this:

But how does a website get access to your Twitter account without requiring your username or password? That’s exactly what OAuth helps with. OAuth is a “a secure authorization protocol that deals with the authorization of third party application to access the user data without exposing their password”.
Where is OAuth used?
Let’s say I’m building a site where I want people to log in and allow people to see their most popular tweets over the past year. Instead of creating a new login system specific to my site, it would make sense to use their existing Twitter account to login, right? The problem is, a new user shouldn’t trust a web service with their Twitter username and password. By providing a “Sign in with Twitter” button, I allow new users to use their existing Twitter account to authenticate with my application without sharing their Twitter credentials with me.
How OAuth works behind the scenes
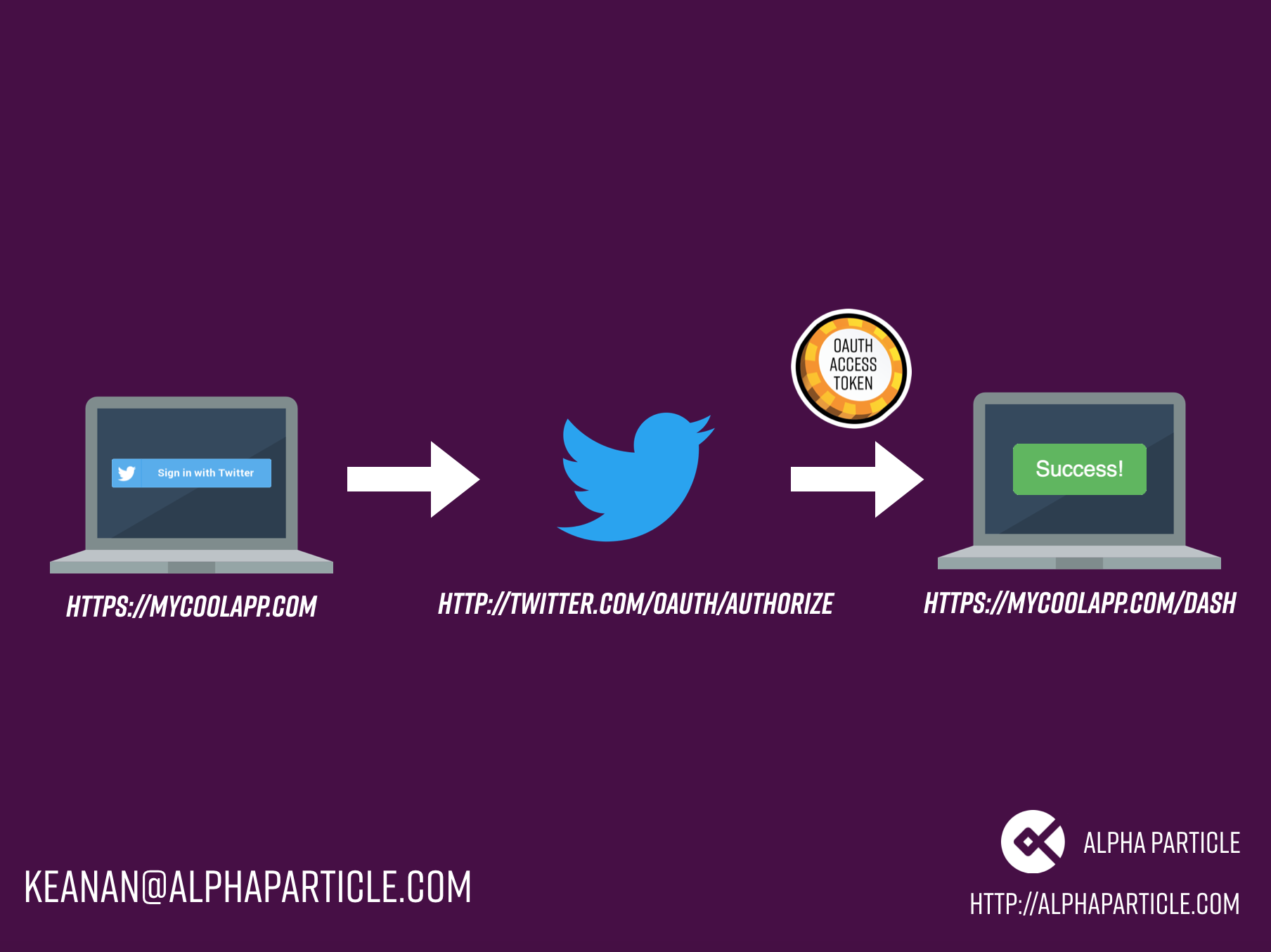
There are three important pieces in any OAuth transaction: the client (my “best tweets” application in our example), the provider (Twitter), and the owner (the user trying to login to my app). To enable OAuth, I have to tell Twitter I’m going to let people login with their service and provide them a redirect URL. A redirect URL is where I want Twitter to redirect the user after they’re done logging in and approving my app for access. In exchange, Twitter will give me a set of tokens and keys needed to make the request and confirm that it’s my app making the login request.
Once all this is set up, we can start the login process. When our user clicks the “Sign in with Twitter” button, my site directs them to Twitter and gives Twitter our App ID. Twitter asks the user to confirm they’re logging in to my app and redirects them back to the redirect URL that I specified. My app also gets a token that confirms the user has authenticated with Twitter. I can store this token and use it to retrieve the information about the user that they’ve approved me to access. My app has now authenticated through Twitter without providing me their Twitter credentials.
What are some of the benefits of OAuth over just general API access?
One of the biggest benefits of OAuth is that a user can grant a service certain permissions. When authenticating, the owner will usually see a dialog from the OAuth provider:
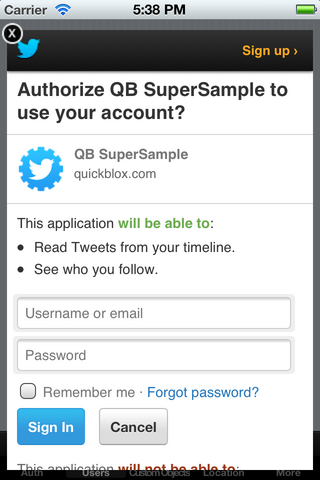
This is helpful as it gives the user information about how exactly I’m going to use their account. In the above example, it would be good to know that the app I’m authorizing can’t post tweets to my timeline impersonating me. For social networks implementing plugins or add-ons, OAuth can be a great way to allow access to untrusted services.
How can OAuth be useful to your business?
One concrete example where OAuth can be useful is systems integration. For businesses with microservices or different systems deployed that need to share credentials, OAuth can provide the framework for these to communicate. Usually, we see credential-sharing between applications that’s inherently insecure. Deploying OAuth can help secure these services while allowing them to share the necessary information to keep your systems up and running. If you’d like to chat about whether implementing OAuth might be right for you, use the contact form below or reach out at hello@alphaparticle.com.